
- A+
Kafka集群介绍
Kafka是一个分布式、可扩展、高吞吐量的消息队列系统,广泛应用于日志收集、实时监控、数据管道、流处理等领域。Kafka集群是由多个Kafka服务器组成的集合,它们协同工作以提供高可用性、可扩展性和容错性。
组件介绍
Kafka Brokers:独立服务器,存储处理消息,维护分区副本,处理读写请求;
Zookeeper(旧版):分布式协调服务,管理集群元数据,Kafka 2.4.0前必需;
KRaft模式(新式):Kafka 2.4.0引入,无需Zookeeper,自行管理集群元数据;
Topics:消息类别或feeds,生产者发布,消费者订阅,分类存储消息;
Partitions:主题分区,有序不可变消息序列,分布存储,实现负载均衡和容错;
Replication:数据复制机制,分区多副本,分布不同Broker,保证数据可靠性;
Kafka Connect:数据传输工具,连接Kafka与其他系统,如数据库、日志收集系统;
Kafka Streams:实时流处理库,构建Kafka上流处理应用,实现复杂数据处理;
Producers:消息发送者,应用程序或系统,向Kafka集群发布消息;
Consumers:消息接收者,应用程序或系统,从Kafka集群订阅并处理消息;
Consumer Groups:消费者组,共同消费主题消息,Kafka确保消息只发送给组内一个消费者。集群特点
高可用性:通过多个Broker和Replication机制,Kafka集群可以在某个Broker失败时继续提供服务;
可扩展性:可以轻松添加更多的Broker到集群中,以处理更多的消息和更高的吞吐量;
容错性:Partition和Replication机制确保了在硬件故障或网络问题发生时,数据不会丢失;
高性能:Kafka设计为高吞吐量的消息系统,可以处理数千个消息/秒的传输速率;
分布式:Kafka集群是分布式的,可以在多个数据中心或云区域中部署。应用场景
日志收集:集中存储和处理来自多个源的大量日志数据;
实时监控:实时监控和分析系统指标和事件;
数据管道:在系统之间可靠地传输数据;
流处理:构建实时数据流处理应用程序。
| 主机 | IP | 组件 |
| kafka-node01 | 192.168.22.14 | JDK,Zookeeper,Kafka |
| kafka-node02 | 192.168.22.15 | JDK,Zookeeper,Kafka |
| kafka-node03 | 192.168.22.16 | JDK,Zookeeper,Kafka |
所有节点配置hosts vim /etc/hosts
192.168.22.14 kafka-node01
192.168.22.15 kafka-node02
192.168.22.16 kafka-node03所有节点安装JDK
wget https://repo.huaweicloud.com/java/jdk/8u202-b08/jdk-8u202-linux-x64.tar.gz
tar xvf jdk-8u202-linux-x64.tar.gz -C /usr/local/
ln -s /usr/local/jdk1.8.0_202/ /usr/local/jdk
vim /etc/profile.d/jdk.sh
export JAVA_HOME=/usr/local/jdk
export JRE_HOME=/usr/local/jdk/jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
source /etc/profile搭建Zookeeper集群
所有节点安装Zookeeper
wget https://mirrors.huaweicloud.com/apache/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz
tar zxvf apache-zookeeper-3.5.7-bin.tar.gz
mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper-3.5.7
ln -s /usr/local/zookeeper-3.5.7/ /usr/local/zookeeper
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg修改配置文件zoo.cfg
vim /usr/local/zookeeper/conf/zoo.cfg
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/logs
server.1=kafka-node01:2888:3888
server.2=kafka-node02:2888:3888
server.3=kafka-node03:2888:3888创建数据目录和日志目录
mkdir -p /usr/local/zookeeper/data/
mkdir -p /usr/local/zookeeper/logs/在每个节点创建myid文件
echo 1 > /usr/local/zookeeper/data/myid //kafka-node01执行
echo 2 > /usr/local/zookeeper/data/myid //kafka-node02执行
echo 3 > /usr/local/zookeeper/data/myid //kafka-node03执行Zookeeper开机自启文件
vim /usr/lib/systemd/system/zookeeper.service
[Unit]
Description=Zookeeper Service
After=network.target
[Service]
Type=forking
Environment="JAVA_HOME=/usr/local/jdk"
Environment="ZOOKEEPER_HOME=/usr/local/zookeeper"
Environment="ZOO_LOG_DIR=/usr/local/zookeeper/logs"
Environment="ZOO_CONF_DIR=/usr/local/zookeeper/conf"
ExecStart=/usr/local/zookeeper/bin/zkServer.sh start
ExecStop=/usr/local/zookeeper/bin/zkServer.sh stop
ExecReload=/usr/local/zookeeper/bin/zkServer.sh restart
PIDFile=/usr/local/zookeeper/data/zookeeper_server.pid
Restart=on-failure
[Install]
WantedBy=multi-user.target开机自启并启动Zookeeper
systemctl daemon-reload
systemctl start zookeeper.service
systemctl enable zookeeper.serviceZookeeper配置环境变量
vim /etc/profile.d/zookeeper.sh
export ZK_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZK_HOME/bin
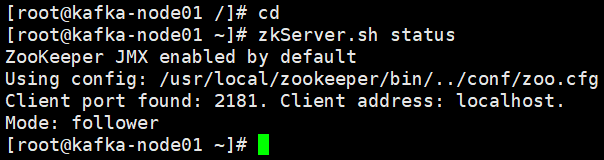
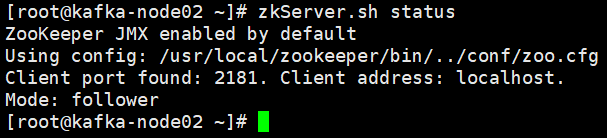
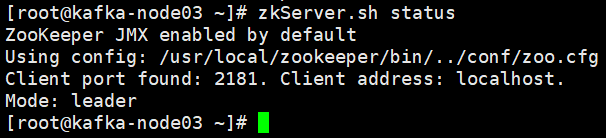
source /etc/profile查看zookeeper服务状态,在每个节点执行zkServer.sh status,leader(领导者)follower(追随者)
搭建Kafka集群
所有节点安装Kafka
wget https://mirrors.huaweicloud.com/apache/kafka/3.8.0/kafka_2.12-3.8.0.tgz
tar zxvf kafka_2.12-3.8.0.tgz -C /usr/local/
ln -s /usr/local/kafka_2.12-3.8.0/ /usr/local/kafka
cp -a /usr/local/kafka/config/server.properties /usr/local/kafka/config/server.properties-bak修改配置文件server.properties
vim /usr/local/kafka/config/server.properties
broker.id=1 //每个Kafka节点的唯一标识,另外两个节点需要修改
log.dirs=/usr/local/kafka/logs //Kafka日志存储路径
zookeeper.connect=192.168.22.14:2181,192.168.22.15:2181,192.168.22.16:2181 //ZooKeeper集群地址
listeners=PLAINTEXT://0.0.0.0:9092 //Kafka服务监听端口
advertised.listeners=PLAINTEXT://kafka-node01:9092 //客户端连接时使用的地址和端口,另外两个节点改为自己的主机名
num.partitions=3 //默认分区数
default.replication.factor=3 //默认副本数,需手动添加
#日志保留策略
log.retention.hours=168 //日志保留小时数
log.retention.bytes=1073741824 //日志保留字节数
log.segment.bytes=1073741824 //日志段大小
log.retention.check.interval.ms=300000 //检查日志保留策略的时间间隔
#性能调优
num.network.threads=3 //处理网络IO的线程数
num.io.threads=8 //处理网络请求的线程数
num.replica.fetchers=1 //副本拉取线程数,需手动添加
socket.send.buffer.bytes=102400 //发送缓冲区大小
socket.receive.buffer.bytes=102400 //接收缓冲区大小
socket.request.max.bytes=104857600 //请求最大字节数Kafka开机自启文件
vim /usr/lib/systemd/system/kafka.service
[Unit]
Description=Apache Kafka Server
Documentation=http://kafka.apache.org/documentation.html
Requires=zookeeper.service
After=zookeeper.service
[Service]
Type=simple
Environment=JAVA_HOME=/usr/local/jdk
Environment=KAFKA_HEAP_OPTS=-Xmx1G -Xms1G
ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh /usr/local/kafka/config/server.properties
Restart=on-failure
RestartSec=30
User=root
Group=root
[Install]
WantedBy=multi-user.target开机自启并启动Kafka
systemctl daemon-reload
systemctl enable --now kafka.serviceKafka配置环境变量
vim /etc/profile.d/kafka.sh
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile验证集群
kafka-topics.sh --bootstrap-server 192.168.22.14:9092,192.168.22.15:9092,192.168.22.16:9092 --create --topic name --partitions 3 --replication-factor 2 //创建一个名为name的主题--bootstrap-server 192.168.22.15:9092:指定Kafka集群的启动服务器地址;
--create:指示脚本执行创建主题的操作;
--topic name:指定要创建的主题名称;
--partitions 3:指定主题的分区数;
--replication-factor 2:指定每个分区的副本数。
kafka-topics.sh --bootstrap-server 192.168.22.14:9092 --describe --topic name //描述Kafka集群中的主题的详细信息--bootstrap-server 192.168.22.14:9092:指定单个Kafka节点地址,客户端通过它发现整个集群;
--describe:获取主题的详细信息;
--topic name:指定要查看的主题名称。

启动一个生产者,发送消息到指定主题
kafka-console-producer.sh --broker-list localhost:9092 --topic name //在kafka-node01执行
启动一个消费者,从指定主题读取消息
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic name --group my-consumer-group //在kafka-node02执行

